COvid-19 Registry of Off-label & New Agents (CORONA)
Background
Given the experience of the Center for Cytokine Storm Treatment & Laboratory (CSTL) at the University of Pennsylvania in studying cytokine storm disorders and identifying treatments for related conditions, the CORONA Project was launched in March 2020 as a largely volunteer-led effort to identify and track all treatments reported to have been used for COVID-19 in an open-source data repository. A report on the first 9,152 patients in CORONA was published in Infectious Diseases & Therapy in May 2020 and was accessed over 10,000 times. CORONA was also highlighted by several media outlets, including CNN, and was cited in a front-page story by the New York Times. By that time, CORONA had become the world’s largest database of COVID-19 treatments, covering 400+ medications that had been administered to over 280,000 patients. All data were made available via our Tableau-based CORONA Viewer, which recorded over 23,000 views, with staff at Google Health, HHS, FDA, and NIH among the regular users. While a few treatments (dexamethasone, heparin, baricitinib) demonstrated efficacy for select COVID-19 patients, more treatments were urgently needed for newly diagnosed and soon-to-be-diagnosed COVID-19 patients while vaccinations were underway and potential SARS-CoV-2 variants emerged.
Goals
The overarching goal of the CORONA project was to advance effective treatments for COVID-19 by highlighting the most promising treatments to pursue, informing optimal clinical trial study design (sample size, target subpopulations), and determining if a drug should move forward to widespread clinical use. To further pursue this goal by the end of 2021, we expanded our work to also integrate pre-clinical and randomized controlled trial data. We believed that this expanded focus would allow us to more quickly advance promising treatments to clinical care that were supported by broader research findings. The expanded data were made publicly available through a new viewer called STORM (Systematic Tracker of Off-label/Repurposed Medicines).
Current Status
We continued to utilize data on treatments reported for COVID-19 in the published literature and began to incorporate published pre-clinical and randomized controlled trial data to a greater extent. We also explored new data sources including health insurance claims, electronic health records, and physician-reported data.
After systematically evaluating and tracking data on treatments for COVID-19 for the first two years of the pandemic, the CORONA Project discontinued operations in 2022. See below for the data viewer that is based on data up until 2022.
Frequently Asked Questions
What data sources were used?
Data regarding clinical trial registrations came from international trial registration websites, such as clinicaltrials.gov. Information from these websites was aggregated by COVID-NMA, and the aggregated data were exported for use in the CORONA Project.
COVID-NMA: Thu Van Nguyen, Gabriel Ferrand, Sarah Cohen-Boulakia, Ruben Martinez, Philipp Kapp, Emmanuel Coquery, … for the COVID-NMA consortium. (2020). RCT studies on preventive measures and treatments for COVID-19 [Data set]. Zenodo. http://doi.org/10.5281/zenodo.4266528
Information about treatment guidelines, such as those issued by the National Institutes of Health, was found on the website of the institutions providing guidelines.
Data from published papers came directly from the publications, as extracted by the CORONA Project’s data coordinators. Data were extracted as provided by the studies’ authors. However, errors could have occurred.
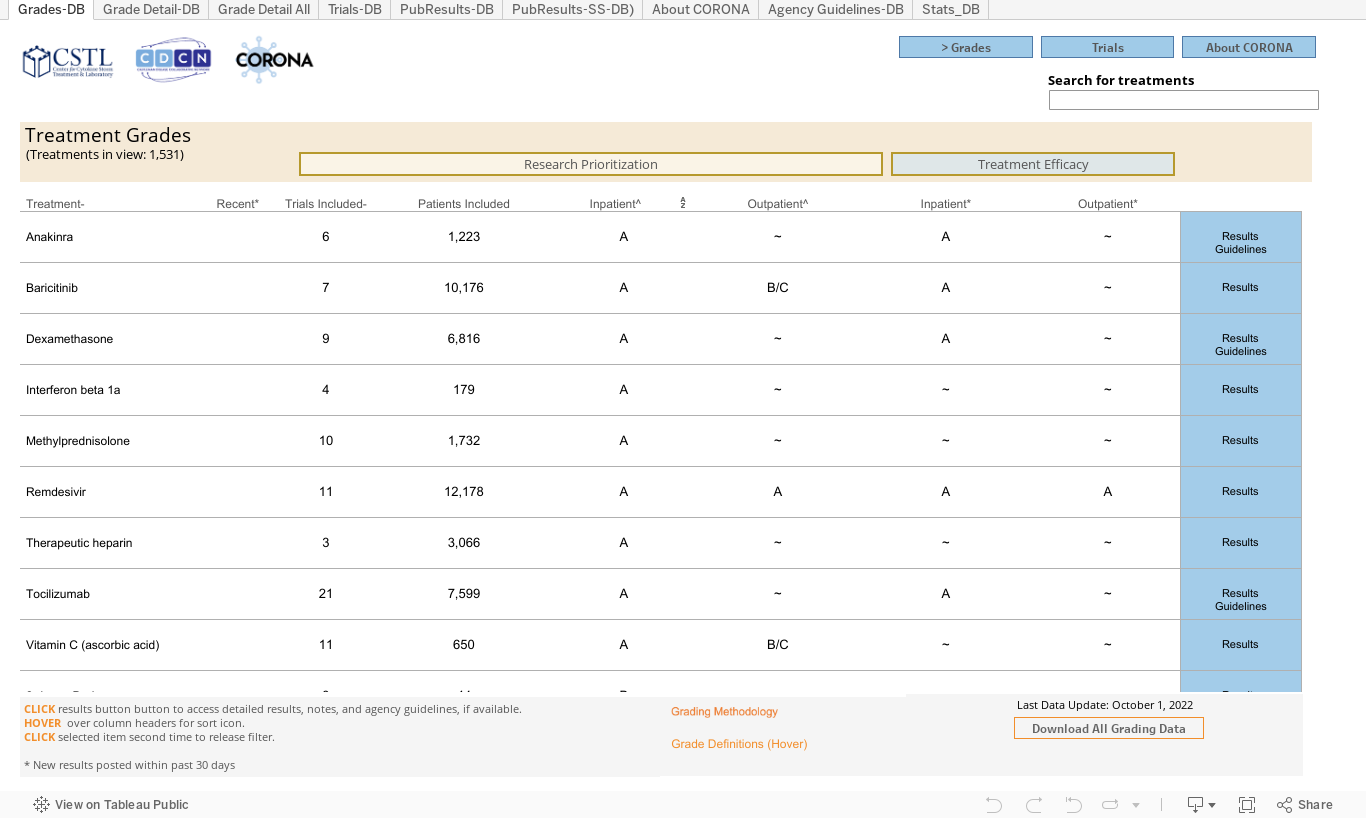
What was the Research Prioritization grade?
The Research Prioritization (RP) grade was based on evidence from published randomized controlled trials. An evidence synthesis was performed for each drug or combination of drugs. If drugs were used in both the inpatient and outpatient settings, separate evidence syntheses were performed for each clinical setting. Each drug-setting received an overall RP grade consisting of 1) a treatment effect assessment (likely beneficial, benefit unknown, not likely beneficial) and 2) a certainty of evidence assessment (high certainty, moderate/low certainty). These grades were presented as letter grades for simplified comparison. The purpose of the RP grade was to identify promising drugs that required further evaluation.
What did the Research Prioritization grade indicate?
The purpose of the Research Prioritization grade was to identify promising drugs that required further evaluation. “A” treatments were likely beneficial with high certainty. They were generally well-studied and had a known likelihood of benefit. These treatments rarely needed further research. “B” treatments were likely beneficial with moderate to low certainty. They had indicators of benefit, but this determination might have been based on insufficient data. These treatments were well-positioned for further research to better characterize efficacy and should generally be prioritized for additional clinical trials. “B/C” treatments might have had a trend towards benefit, but the data synthesis indicated that the benefit was not yet clear. “C” treatments were not likely beneficial with moderate to low certainty. They did not appear beneficial based on the available data, but there might have been insufficient data to make a robust determination. These treatments were generally not prioritized for further research. “D” treatments were not likely beneficial with high certainty, based on a substantial amount of previous research. In general, “D” treatments did not require further research.
|
Letter Grade |
Definition |
|
A |
Likely beneficial with high certainty |
|
B |
Likely beneficial with moderate to low certainty |
|
B/C |
Grade uncertain |
|
C |
Not likely beneficial with moderate to low certainty |
|
D |
Not likely beneficial with high certainty |
What is the Treatment Efficacy grade?
The Treatment Efficacy (TE) grade was based on evidence from a curated subset of randomized controlled trials. By limiting data to large, peer-reviewed studies, this grade was intended to provide an assessment of the available evidence for use in a clinical setting. In contrast, the Research Prioritization grade included pre-prints, small studies, etc., which might have provided valuable signals about a treatment’s efficacy but were unlikely to be robust enough to guide treatment recommendations with high certainty. In addition to this algorithmic grade, information on international treatment guidelines, such as from the NIH and IDSA, was provided alongside for further context. Note that some treatments were recommended for particular subgroups, such as those on mechanical ventilation. If treatment guidelines recommended that a drug was best used in a particular setting, this was noted in the CORONA viewer along with the treatment efficacy letter grade. The purpose of the TE grade was to serve as an indicator of whether sufficient data existed in support of using a treatment in clinical practice at that time for COVID-19.
How were the Research Prioritization and Treatment Efficacy grades formulated?
The grades were both based on two components, a likelihood of benefit assessment and a certainty of evidence assessment, as described below.
Likelihood of benefit assessment
The treatment effect portion of the overall grade was calculated using two methods:
-
Fisher’s method p-value: Combined P-values of the primary endpoints of each study for a given treatment (as described in https://training.cochrane.org/handbook/current/chapter-10). We analyzed p-values across all studies using Fisher’s method. The test statistic followed a chi-squared distribution, which could be used to calculate a p-value for the null hypothesis that there was no evidence of an effect in at least one study. A p-value of <0.05 indicated that there was evidence of an effect in at least one study. Note that if a study provided a one-sided p-value, it was assumed that the hypothesis was in favor of the treatment under investigation.
-
Proportion of studies with beneficial effect direction: Summarized the effect direction of the primary endpoints of each study. For example, if mortality was lower in the treatment group, the treatment was noted as having a “beneficial” effect for that given endpoint. (“Beneficial” was used only to indicate the direction of effect, not its magnitude or significance.)
We considered including other methods of synthesizing treatment effect, including a true meta-analysis or an analysis focusing on summarizing a select number of effect estimates. However, both methods would have been best used if comparing identical endpoints across multiple studies—e.g., mortality. We extracted multiple data points from all publications, so it was possible to explore the methods in the medium term.
Certainty of evidence assessment
The certainty of evidence for a given treatment was determined by looking at three metrics:
-
Precision: Sample size across all peer-reviewed trials listed in PubMed included in the evidence synthesis (≥500 total patients treated was required for a high certainty of evidence). When calculating total sample size, we considered only articles that were peer-reviewed (to minimize the impact of erroneous results from pre-prints) and listed in PubMed (to minimize the impact of results from unreputable journals). However, pre-prints and those not listed in PubMed were still used for drug effect estimate analysis.
-
Directness of evidence: Number of trials included in the evidence synthesis compared to placebo or standard of care. ≥50% of trials included in the evidence synthesis had to be compared to placebo or standard of care for a high certainty of evidence.
-
Publication quality: Number of trials included in the evidence synthesis published in a journal that was indexed in PubMed. ≥75% of trials included in the evidence synthesis had to be published in a journal that was indexed in PubMed for a high certainty of evidence.
The certainty of evidence for a given treatment was determined by incorporating each of the factors above. A “high” certainty of evidence assessment was for treatments that met the threshold for all the factors above. A “moderate” certainty of evidence was reserved for treatments that met some but not all the thresholds, and a “low” certainty of evidence was assigned to treatments that met none.
What did a trial ID starting with XXX indicate?
Trials that had a trial ID beginning with XXX were not known to have a trial registration number. This might have been because the published paper did not indicate a trial registration number, and data coordinators could not link it to a known trial. It might also have occurred if a trial was run without being registered. Errors might have occurred during the data extraction process.
How could the data be used?
Data could be used freely, and no permission was required. However, we requested attribution when using the manually extracted data (including study endpoint values, p-values, effect estimates, etc.).
Who should I contact with questions or concerns?
The data in this project were extracted manually from published papers by data coordinators. Errors might have occurred.
If you had any questions, please email Tracey Sikora at tsikora@pennmedicine.upenn.edu.